Kristy Chu
May 29, 2023




Buchhaltungsteams werden ständig mit endlosen To-Do-Listen mit unmöglichen Fristen bombardiert. Das Ziel von FloQast ist es, zur Rationalisierung der Prozess zum Monatsende abschließen (und mehr!) , und ein wichtiger Teil dieses Prozesses ist die automatische nächtliche Aktualisierung. Wir aktualisieren ständig Daten aus externen Quellen wie OneDrive, sodass die Daten unserer Benutzer korrekt aussehen, wenn sie sich bei der Anwendung anmelden.

Sie können sich also vorstellen, dass unsere Panik ausbrach, als einer unserer größten Kunden, nennen wir ihn Company ABC, berichtete, dass ein erheblicher Ausfallrate bei ihren nächtlichen Auffrischungen.

Basierend auf unseren Fehlerprotokollen konnte unser Team die wahrscheinliche Ursache für Drosselungsprobleme ermitteln, die von ihrem Speicheranbieter OneDrive ausgelöst wurden.

Um zu verstehen, wie das Problem behoben werden kann, wollen wir uns ein besseres Bild davon machen, wie die nächtliche Aktualisierung funktioniert.
Jeden Abend um Mitternacht, ein Cron Der Job wird gestartet und Nachrichten werden in die Nachtwarteschlange eingefügt. Jede Nachricht steht für den Prozess eines Unternehmens zur Synchronisierung seiner Datensätze. Unsere Mitarbeiter ziehen diese Nachrichten aus der Warteschlange, um sie mit den entsprechenden Anmeldeinformationen des Speicheranbieters und/oder ERP abzuarbeiten (Unternehmensressourcenplanung). In der Regel werden mehrere Nachrichten nach Kundennummer zusammengefasst. Bei Nachrichten, die gebündelt sind, arbeiten unsere Mitarbeiter sie nacheinander ab, um Kollisionen mit Anmeldeinformationen zu vermeiden.
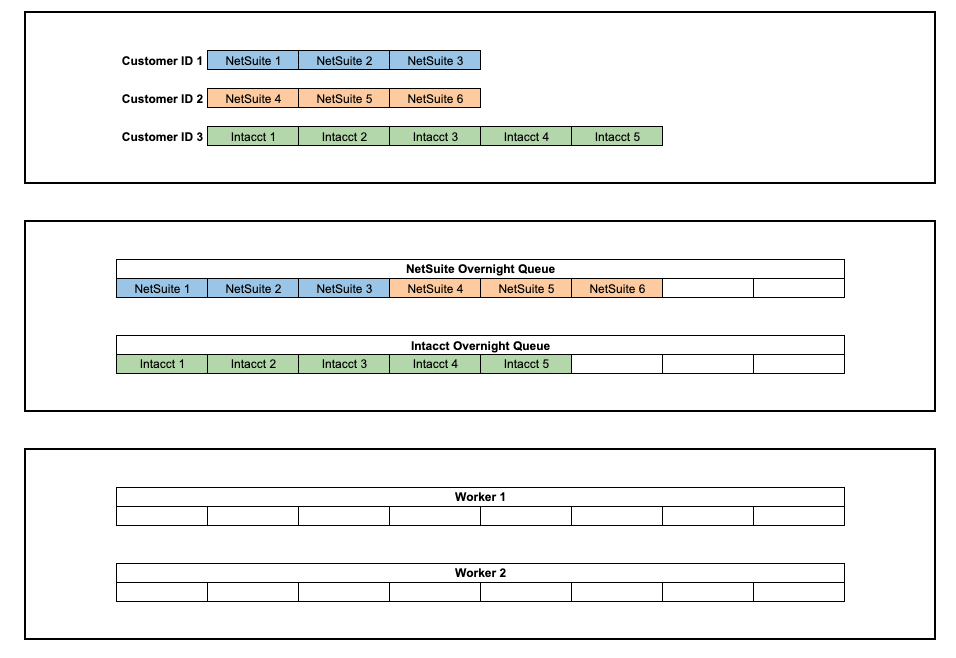

Aufgrund der Größe von Unternehmen ABC verfügen sie über eine Einrichtung mit mehreren Kunden-IDs, die dieselben OneDrive-Anmeldeinformationen verwenden. Die Art und Weise, wie unsere nächtliche Aktualisierung eingerichtet ist, spammt diese Anmeldeinformationen, was dazu führt, dass ihre Anfragen nach Speicherdaten gedrosselt werden.
Wir haben mehrere mögliche Lösungen untersucht und beschlossen, Nachrichten mit OneDrive-Anmeldeinformationen unterschiedlich zu gruppieren. Anstatt Nachrichten anhand der Kunden-ID zu gruppieren, haben wir diese Nachrichten nach einer Eigenschaft namens gruppiert Serviceressourcen-ID, was die URL darstellt, die für API-Aufrufe verwendet wird, um Daten von einem bestimmten OneDrive-Mandanten abzurufen.

Die obige Lösung bringt uns jedoch zu Problem #2: Wenn Nachrichten, die zu derselben Gruppe gehören, in verschiedenen Warteschlangen landen. Wir haben viele Kunden, darunter Company ABC, die mehrere ERPs in ihren Konten verwenden. Jeder ERP-Anbieter, den wir unterstützen, hat seine eigene entsprechende Warteschlange (z. B. fallen NetSuite-Nachrichten nur in die NetSuite-Warteschlange), und die gruppierte Zuordnung wird nur innerhalb einer einzigen Warteschlange angewendet, was bedeutet, dass eine NetSuite-Gruppe mit der Gruppen-ID OneDrive1234 nicht als dieselbe Gruppe betrachtet wird wie eine Intacct-Gruppe mit der Gruppen-ID OneDrive1234, obwohl sie technisch gesehen dieselbe Gruppe sind. Infolgedessen werden Nachrichten derselben Gruppe, die sich in verschiedenen Warteschlangen befinden, immer noch gleichzeitig von unseren Mitarbeitern verarbeitet, und wir stoßen erneut auf das Drosselungsproblem.
Daher haben wir eine Logik hinzugefügt, um Nachrichten erneut in die Warteschlange zu stellen, wenn die Anmeldeinformationen verwendet werden. Diese Nachrichten werden die ganze Nacht über kontinuierlich in die Warteschlange gestellt, bis die Anmeldeinformationen zur Verwendung verfügbar sind.


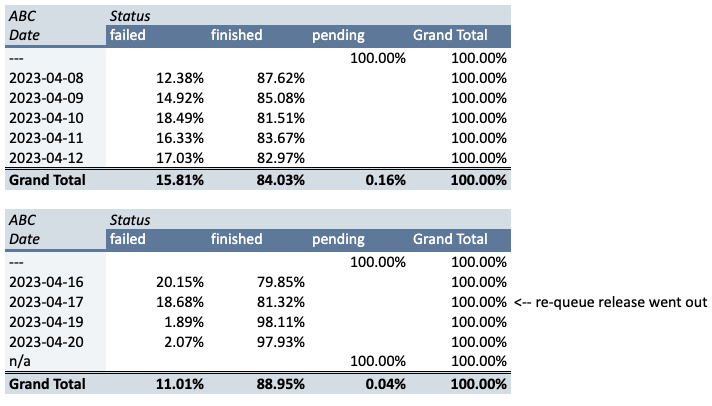
Wir haben in einer Reihe von Versionen Änderungen vorgenommen und bereits Verbesserungen bei der nächtlichen Aktualisierung von Company ABC festgestellt, die nur durch die Verwendung des Serviceressourcen-ID Gruppierung — die Erfolgsrate bei nächtlichen Aktualisierungen stieg sofort von 20% auf 80%. Die Re-Queue-Logik brachte die Erfolgsquote auf satte 98%.
Das erfordert natürlich eine Feier!

Seit der Einführung der Logik der erneuten Warteschlangen mussten wir feststellen, dass es bis zum Nachmittag des nächsten Werktages dauern würde, bis die Warteschlange über Nacht leer war. Wir waren der Meinung, dass dieses Timing möglicherweise zu Problemen für unsere Benutzer führen könnte, da sie den Aktualisierungsprozess für ein Unternehmen in der Anwendung manuell auslösen, wenn sich die Nachricht dieses Unternehmens immer noch in der Warteschlange über Nacht befindet. Daher haben wir vor Kurzem Änderungen an abgelaufenen Nachrichten veröffentlicht, die sich seit über 8 Stunden in der Warteschlange über Nacht in der Warteschlange befinden, sodass unsere Benutzer weniger wahrscheinlich während des Arbeitstages auf Probleme mit der Aktualisierung stoßen. Wir wussten, dass die Erfolgsquote von 98% wahrscheinlich sinken würde, aber bis jetzt sind keine Beschwerden oder Probleme mit dem Produktsupport eingegangen, also betrachten wir das als großen Gewinn.
